Number of Sequence Reads Is Not Good Indicator of Sample Quality
| Internet media blazon | text/apparently, chemical/seq-na-fastq |
|---|---|
| Developed by | Wellcome Trust Sanger Institute |
| Initial release | ~2000 |
| Blazon of format | Bioinformatics |
| Extended from | ASCII and FASTA format |
| Website | maq |
FASTQ format is a text-based format for storing both a biological sequence (ordinarily nucleotide sequence) and its corresponding quality scores. Both the sequence letter and quality score are each encoded with a single ASCII grapheme for brevity.
Information technology was originally developed at the Wellcome Trust Sanger Institute to bundle a FASTA formatted sequence and its quality data, just has recently go the de facto standard for storing the output of high-throughput sequencing instruments such as the Illumina Genome Analyzer.[1]
Format [edit]
A FASTQ file normally uses iv lines per sequence.
- Line 1 begins with a '@' graphic symbol and is followed by a sequence identifier and an optional description (like a FASTA title line).
- Line 2 is the raw sequence letters.
- Line 3 begins with a '+' character and is optionally followed by the aforementioned sequence identifier (and any description) once more.
- Line 4 encodes the quality values for the sequence in Line 2, and must incorporate the same number of symbols as letters in the sequence.
A FASTQ file containing a single sequence might await like this:
@SEQ_ID GATTTGGGGTTCAAAGCAGTATCGATCAAATAGTAAATCCATTTGTTCAACTCACAGTTT + !''*((((***+))%%%++)(%%%%).1***-+*''))**55CCF>>>>>>CCCCCCC65
The byte representing quality runs from 0x21 (everyman quality; '!' in ASCII) to 0x7e (highest quality; '~' in ASCII). Here are the quality value characters in left-to-right increasing society of quality (ASCII):
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~ The original Sanger FASTQ files also allowed the sequence and quality strings to be wrapped (split over multiple lines), but this is mostly discouraged[ citation needed ] as it can brand parsing complicated due to the unfortunate choice of "@" and "+" every bit markers (these characters can also occur in the quality cord).
Illumina sequence identifiers [edit]
Sequences from the Illumina software use a systematic identifier:
@HWUSI-EAS100R:vi:73:941:1973#0/ane
| HWUSI-EAS100R | the unique instrument proper noun |
|---|---|
| 6 | flowcell lane |
| 73 | tile number inside the flowcell lane |
| 941 | 'x'-coordinate of the cluster inside the tile |
| 1973 | 'y'-coordinate of the cluster within the tile |
| #0 | alphabetize number for a multiplexed sample (0 for no indexing) |
| /1 | the fellow member of a pair, /1 or /2 (paired-finish or mate-pair reads only) |
Versions of the Illumina pipeline since i.4 appear to employ #NNNNNN instead of #0 for the multiplex ID, where NNNNNN is the sequence of the multiplex tag.
With Casava 1.8 the format of the '@' line has inverse:
@EAS139:136:FC706VJ:2:2104:15343:197393 one:Y:18:ATCACG
| EAS139 | the unique instrument name |
|---|---|
| 136 | the run id |
| FC706VJ | the flowcell id |
| ii | flowcell lane |
| 2104 | tile number within the flowcell lane |
| 15343 | 'x'-coordinate of the cluster within the tile |
| 197393 | 'y'-coordinate of the cluster within the tile |
| 1 | the member of a pair, 1 or ii (paired-end or mate-pair reads only) |
| Y | Y if the read is filtered (did not pass), N otherwise |
| 18 | 0 when none of the control bits are on, otherwise it is an even number |
| ATCACG | index sequence |
Note that more than recent versions of Illumina software output a sample number (as taken from the sample sail) in identify of an index sequence. For example, the following header might appear in the beginning sample of a batch:
@EAS139:136:FC706VJ:2:2104:15343:197393 ane:N:xviii:1
NCBI Sequence Read Archive [edit]
FASTQ files from the INSDC Sequence Read Archive oftentimes include a description, e.g.
@SRR001666.1 071112_SLXA-EAS1_s_7:5:i:817:345 length=36 GGGTGATGGCCGCTGCCGATGGCGTCAAATCCCACC +SRR001666.1 071112_SLXA-EAS1_s_7:5:1:817:345 length=36 IIIIIIIIIIIIIIIIIIIIIIIIIIIIII9IG9IC
In this example there is an NCBI-assigned identifier, and the description holds the original identifier from Solexa/Illumina (as described above) plus the read length. Sequencing was performed in paired-cease mode (~500bp insert size), see SRR001666. The default output format of fastq-dump produces entire spots, containing whatever technical reads and typically single or paired-end biological reads.
$ fastq-dump.two.9.0 -Z -X 2 SRR001666 Read 2 spots for SRR001666 Written 2 spots for SRR001666 @SRR001666.1 071112_SLXA-EAS1_s_7:v:1:817:345 length=72 GGGTGATGGCCGCTGCCGATGGCGTCAAATCCCACCAAGTTACCCTTAACAACTTAAGGGTTTTCAAATAGA +SRR001666.1 071112_SLXA-EAS1_s_7:5:1:817:345 length=72 IIIIIIIIIIIIIIIIIIIIIIIIIIIIII9IG9ICIIIIIIIIIIIIIIIIIIIIDIIIIIII>IIIIII/ @SRR001666.2 071112_SLXA-EAS1_s_7:5:i:801:338 length=72 GTTCAGGGATACGACGTTTGTATTTTAAGAATCTGAAGCAGAAGTCGATGATAATACGCGTCGTTTTATCAT +SRR001666.two 071112_SLXA-EAS1_s_7:five:1:801:338 length=72 IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII6IBIIIIIIIIIIIIIIIIIIIIIIIGII>IIIII-I)8I Modern usage of FASTQ almost always involves splitting the spot into its biological reads, every bit described in submitter-provided metadata:
$ fastq-dump -X 2 SRR001666 --split-3 Read two spots for SRR001666 Written 2 spots for SRR001666 $ head SRR001666_1.fastq SRR001666_2.fastq ==> SRR001666_1.fastq <== @SRR001666.1 071112_SLXA-EAS1_s_7:5:1:817:345 length=36 GGGTGATGGCCGCTGCCGATGGCGTCAAATCCCACC +SRR001666.1 071112_SLXA-EAS1_s_7:5:1:817:345 length=36 IIIIIIIIIIIIIIIIIIIIIIIIIIIIII9IG9IC @SRR001666.2 071112_SLXA-EAS1_s_7:5:1:801:338 length=36 GTTCAGGGATACGACGTTTGTATTTTAAGAATCTGA +SRR001666.two 071112_SLXA-EAS1_s_7:five:one:801:338 length=36 IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII6IBI ==> SRR001666_2.fastq <== @SRR001666.1 071112_SLXA-EAS1_s_7:five:i:817:345 length=36 AAGTTACCCTTAACAACTTAAGGGTTTTCAAATAGA +SRR001666.1 071112_SLXA-EAS1_s_7:v:1:817:345 length=36 IIIIIIIIIIIIIIIIIIIIDIIIIIII>IIIIII/ @SRR001666.2 071112_SLXA-EAS1_s_7:5:1:801:338 length=36 AGCAGAAGTCGATGATAATACGCGTCGTTTTATCAT +SRR001666.2 071112_SLXA-EAS1_s_7:v:i:801:338 length=36 IIIIIIIIIIIIIIIIIIIIIIGII>IIIII-I)8I When nowadays in the archive, fastq-dump can endeavor to restore read names to original format. NCBI does not store original read names by default:
$ fastq-dump -X 2 SRR001666 --divide-3 --origfmt Read 2 spots for SRR001666 Written 2 spots for SRR001666 $ caput SRR001666_1.fastq SRR001666_2.fastq ==> SRR001666_1.fastq <== @071112_SLXA-EAS1_s_7:5:ane:817:345 GGGTGATGGCCGCTGCCGATGGCGTCAAATCCCACC +071112_SLXA-EAS1_s_7:5:1:817:345 IIIIIIIIIIIIIIIIIIIIIIIIIIIIII9IG9IC @071112_SLXA-EAS1_s_7:five:ane:801:338 GTTCAGGGATACGACGTTTGTATTTTAAGAATCTGA +071112_SLXA-EAS1_s_7:5:i:801:338 IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII6IBI ==> SRR001666_2.fastq <== @071112_SLXA-EAS1_s_7:5:one:817:345 AAGTTACCCTTAACAACTTAAGGGTTTTCAAATAGA +071112_SLXA-EAS1_s_7:5:1:817:345 IIIIIIIIIIIIIIIIIIIIDIIIIIII>IIIIII/ @071112_SLXA-EAS1_s_7:5:ane:801:338 AGCAGAAGTCGATGATAATACGCGTCGTTTTATCAT +071112_SLXA-EAS1_s_7:5:one:801:338 IIIIIIIIIIIIIIIIIIIIIIGII>IIIII-I)8I In the example above, the original read names were used rather than the accessioned read proper noun. NCBI accessions runs and the reads they contain. Original read names, assigned past sequencers, are able to office as locally unique identifiers of a read, and convey exactly as much information as a series number. The ids above were algorithmically assigned based upon run information and geometric coordinates. Early SRA loaders parsed these ids and stored their decomposed components internally. NCBI stopped recording read names because they are frequently modified from the vendors' original format in order to acquaintance some boosted information meaningful to a item processing pipeline, and this acquired name format violations that resulted in a high number of rejected submissions. Without a clear schema for read names, their function remains that of a unique read id, conveying the same corporeality of information every bit a read series number. See diverse SRA Toolkit issues for details and discussions.
Also note that fastq-dump converts this FASTQ data from the original Solexa/Illumina encoding to the Sanger standard (see encodings below). This is because the SRA serves equally a repository for NGS information, rather than format. The various *-dump tools are capable of producing data in several formats from the aforementioned source. The requirements for doing and then have been dictated past users over several years, with the majority of early demand coming from the thousand Genomes Project.
Variations [edit]
Quality [edit]
A quality value Q is an integer mapping of p (i.e., the probability that the corresponding base phone call is incorrect). Two unlike equations have been in use. The first is the standard Sanger variant to appraise reliability of a base call, otherwise known as Phred quality score:

The Solexa pipeline (i.e., the software delivered with the Illumina Genome Analyzer) before used a different mapping, encoding the odds p/(1-p) instead of the probability p:

Although both mappings are asymptotically identical at higher quality values, they differ at lower quality levels (i.eastward., approximately p > 0.05, or equivalently, Q < 13).
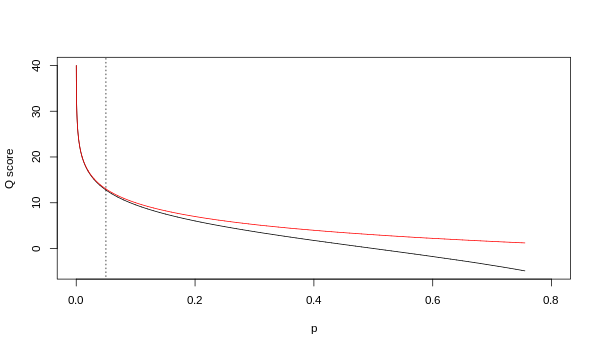
Relationship betwixt Q and p using the Sanger (red) and Solexa (blackness) equations (described above). The vertical dotted line indicates p = 0.05, or equivalently, Q ≈ thirteen.
At times at that place has been disagreement virtually which mapping Illumina actually uses. The user guide (Appendix B, page 122) for version 1.iv of the Illumina pipeline states that: "The scores are defined as Q=x*log10(p/(1-p)) [sic], where p is the probability of a base call respective to the base in question".[2] In retrospect, this entry in the manual appears to take been an error. The user guide (What'southward New, folio 5) for version 1.v of the Illumina pipeline lists this description instead: "Of import Changes in Pipeline v1.3 [sic]. The quality scoring scheme has changed to the Phred [i.e., Sanger] scoring scheme, encoded every bit an ASCII character past adding 64 to the Phred value. A Phred score of a base is: , where due east is the estimated probability of a base being incorrect.[iii]

Encoding [edit]
- Sanger format can encode a Phred quality score from 0 to 93 using ASCII 33 to 126 (although in raw read data the Phred quality score rarely exceeds 60, higher scores are possible in assemblies or read maps). Also used in SAM format.[four] Coming to the stop of February 2011, Illumina'southward newest version (one.8) of their pipeline CASAVA will directly produce fastq in Sanger format, according to the announcement on seqanswers.com forum.[5]
- PacBio HiFi reads, which are typically stored in SAM/BAM format, use the Sanger convention: Phred quality scores from 0 to 93 are encoded using ASCII 33 to 126. Raw PacBio subreads apply the aforementioned convention simply typically assign a placeholder base quality (Q0) to all bases in the read.[six]
- Solexa/Illumina i.0 format tin can encode a Solexa/Illumina quality score from -five to 62 using ASCII 59 to 126 (although in raw read data Solexa scores from -5 to twoscore only are expected)
- Starting with Illumina one.iii and earlier Illumina 1.8, the format encoded a Phred quality score from 0 to 62 using ASCII 64 to 126 (although in raw read data Phred scores from 0 to xl just are expected).
- Starting in Illumina i.5 and earlier Illumina 1.viii, the Phred scores 0 to 2 have a slightly different pregnant. The values 0 and 1 are no longer used and the value 2, encoded by ASCII 66 "B", is used likewise at the end of reads every bit a Read Segment Quality Control Indicator.[vii] The Illumina transmission[8] (page 30) states the post-obit: If a read ends with a segment of mostly low quality (Q15 or below), so all of the quality values in the segment are replaced with a value of ii (encoded as the letter B in Illumina's text-based encoding of quality scores)... This Q2 indicator does not predict a specific error rate, but rather indicates that a specific final portion of the read should non be used in further analyses. Also, the quality score encoded as "B" alphabetic character may occur internally within reads at least as tardily as pipeline version 1.6, as shown in the following example:
@HWI-EAS209_0006_FC706VJ:v:58:5894:21141#ATCACG/one TTAATTGGTAAATAAATCTCCTAATAGCTTAGATNTTACCTTNNNNNNNNNNTAGTTTCTTGAGATTTGTTGGGGGAGACATTTTTGTGATTGCCTTGAT +HWI-EAS209_0006_FC706VJ:5:58:5894:21141#ATCACG/1 efcfffffcfeefffcffffffddf`feed]`]_Ba_^__[YBBBBBBBBBBRTT\]][]dddd`ddd^dddadd^BBBBBBBBBBBBBBBBBBBBBBBB
An alternative interpretation of this ASCII encoding has been proposed.[ix] Besides, in Illumina runs using PhiX controls, the character 'B' was observed to represent an "unknown quality score". The error rate of 'B' reads was roughly 3 phred scores lower the mean observed score of a given run.
- Starting in Illumina 1.8, the quality scores accept basically returned to the employ of the Sanger format (Phred+33).
For raw reads, the range of scores volition depend on the technology and the base caller used, but will typically be up to 41 for recent Illumina chemistry. Since the maximum observed quality score was previously simply 40, diverse scripts and tools break when they come across information with quality values larger than twoscore. For processed reads, scores may be even higher. For example, quality values of 45 are observed in reads from Illumina's Long Read Sequencing Service (previously Moleculo).
SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS..................................................... ..........................XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX...................... ...............................IIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIII...................... ................................. JJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJ..................... LLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLL.................................................... PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPPPP PPPP !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~ | | | | | | 33 59 64 73 104 126 0........................26...31.......40 -v....0........9.............................xl 0........9.............................40 3.....9..............................41 0.two......................26...31........41 0..................xx........30........40........50..........................................93
S - Sanger Phred+33, raw reads typically (0, 40) X - Solexa Solexa+64, raw reads typically (-5, 40) I - Illumina ane.3+ Phred+64, raw reads typically (0, 40) J - Illumina ane.v+ Phred+64, raw reads typically (3, 41) with 0=unused, one=unused, ii=Read Segment Quality Control Indicator (assuming) (Note: Come across discussion above). 50 - Illumina i.eight+ Phred+33, raw reads typically (0, 41) P - PacBio Phred+33, HiFi reads typically (0, 93)
Color space [edit]
For SOLiD data, the sequence is in color space, except the commencement position. The quality values are those of the Sanger format. Alignment tools differ in their preferred version of the quality values: some include a quality score (fix to 0, i.due east. '!') for the leading nucleotide, others exercise not. The sequence read annal includes this quality score.
Simulation [edit]
FASTQ read simulation has been approached past several tools.[ten] [11] A comparing of those tools can be seen here.[12]
Pinch [edit]
General compressors [edit]
General-purpose tools such as Gzip and bzip2 regard FASTQ equally a apparently text file and issue in suboptimal compression ratios. NCBI's Sequence Read Annal encodes metadata using the LZ-77 scheme. Full general FASTQ compressors typically compress distinct fields (read names, sequences, comments, and quality scores) in a FASTQ file separately; these include Genozip,[13] DSRC and DSRC2, FQC, LFQC, Fqzcomp, and Slimfastq.
Reads [edit]
Having a reference genome effectually is user-friendly because then instead of storing the nucleotide sequences themselves, ane tin just marshal the reads to the reference genome and store the positions (pointers) and mismatches; the pointers tin can and so be sorted according to their club in the reference sequence and encoded, e.chiliad., with run-length encoding. When the coverage or the repeat content of the sequenced genome is loftier, this leads to a loftier compression ratio. Different the SAM/BAM formats, FASTQ files do not specify a reference genome. Alignment-based FASTQ compressors supports the use of either user-provided or de novo assembled reference: LW-FQZip uses a provided reference genome and Quip, Leon, m-Path and KIC perform de novo assembly using a de Bruijn graph-based approach. Genozip[13] can optionally use a reference if the user provides one, which may be a unmarried- or multi-species reference file.
Explicit read mapping and de novo assembly are typically boring. Reordering-based FASTQ compressors first cluster reads that share long substrings and and then independently shrink reads in each cluster later reordering them or assembling them into longer contigs, achieving perhaps the all-time trade-off between the running time and compression rate. SCALCE is the first such tool, followed past Orcom and Mince. BEETL uses a generalized Burrows–Wheeler transform for reordering reads, and HARC achieves better performance with hash-based reordering. AssemblTrie instead assembles reads into reference trees with as few total number of symbols equally possible in the reference.[14] [15]
Benchmarks for these tools are available in.[sixteen]
Quality values [edit]
Quality values account for about one-half of the required disk space in the FASTQ format (before pinch), and therefore the compression of the quality values can significantly reduce storage requirements and speed up analysis and transmission of sequencing information. Both lossless and lossy compression are recently being considered in the literature. For example, the algorithm QualComp[17] performs lossy compression with a charge per unit (number of bits per quality value) specified by the user. Based on charge per unit-distortion theory results, it allocates the number of bits so as to minimize the MSE (mean squared error) between the original (uncompressed) and the reconstructed (after compression) quality values. Other algorithms for compression of quality values include SCALCE[xviii] and Fastqz.[19] Both are lossless compression algorithms that provide an optional controlled lossy transformation approach. For example, SCALCE reduces the alphabet size based on the observation that "neighboring" quality values are similar in full general. For a benchmark, run into.[20]
As of the HiSeq 2500 Illumina gives the pick to output qualities that have been fibroid grained into quality bins. The binned scores are computed directly from the empirical quality score table, which is itself tied to the hardware, software and chemical science that were used during the sequencing experiment.[21]
Genozip[13] uses its DomQual algorithm to shrink binned quality scores, such every bit those generated by Illumina or by Genozip's own --optimize choice which generates bins similar to Illumina.
Encryption [edit]
Genozip[13] encrypts FASTQ files (every bit well as other genomic formats), by applying the standard AES encryption at its about secure level of 256 bits (--password option).
Cryfa[22] uses AES encryption and enables to compact data besides encryption. It can likewise address FASTA files.
File extension [edit]
There is no standard file extension for a FASTQ file, only .fq and .fastq are commonly used.
Format converters [edit]
- Biopython version 1.51 onwards (interconverts Sanger, Solexa and Illumina 1.3+)
- EMBOSS version half dozen.1.0 patch ane onwards (interconverts Sanger, Solexa and Illumina 1.3+)
- BioPerl version 1.half dozen.1 onwards (interconverts Sanger, Solexa and Illumina ane.3+)
- BioRuby version 1.four.0 onwards (interconverts Sanger, Solexa and Illumina 1.3+)
- BioJava version 1.7.1 onwards (interconverts Sanger, Solexa and Illumina ane.3+)
See besides [edit]
- The FASTA format, used to stand for genome sequences.
- The SAM format, used to stand for genome sequencer reads that have been aligned to genome sequences.
- The GVF format (Genome Variation Format), an extension based on the GFF3 format.
References [edit]
- ^ Cock, P. J. A.; Fields, C. J.; Goto, North.; Heuer, M. L.; Rice, P. 1000. (2009). "The Sanger FASTQ file format for sequences with quality scores, and the Solexa/Illumina FASTQ variants". Nucleic Acids Inquiry. 38 (6): 1767–1771. doi:10.1093/nar/gkp1137. PMC2847217. PMID 20015970.
- ^ Sequencing Analysis Software User Guide: For Pipeline Version 1.four and CASAVA Version i.0, dated April 2009 PDF Archived June 10, 2010, at the Wayback Machine
- ^ Sequencing Analysis Software User Guide: For Pipeline Version 1.five and CASAVA Version 1.0, dated Baronial 2009 PDF [ dead link ]
- ^ Sequence/Alignment Map format Version 1.0, dated August 2009 PDF
- ^ Seqanswer'southward topic of skruglyak, dated Jan 2011 website
- ^ PacBio BAM format specification 10.0.0 https://pacbiofileformats.readthedocs.io/en/10.0/BAM.html#qual
- ^ Illumina Quality Scores, Tobias Mann, Bioinformatics, San Diego, Illumina http://seqanswers.com/forums/showthread.php?t=4721
- ^ Using Genome Analyzer Sequencing Command Software, Version 2.6, Itemize # SY-960-2601, Part # 15009921 Rev. A, November 2009 http://watson.nci.nih.gov/solexa/Using_SCSv2.6_15009921_A.pdf [ dead link ]
- ^ SolexaQA project website
- ^ Huang, Due west; Li, 50; Myers, J. R.; Marth, G. T. (2012). "Art: A next-generation sequencing read simulator". Bioinformatics. 28 (4): 593–4. doi:x.1093/bioinformatics/btr708. PMC3278762. PMID 22199392.
- ^ Pratas, D; Pinho, A. J.; Rodrigues, J. M. (2014). "XS: A FASTQ read simulator". BMC Research Notes. 7: 40. doi:10.1186/1756-0500-7-forty. PMC3927261. PMID 24433564.
- ^ Escalona, Merly; Rocha, Sara; Posada, David (2016). "A comparison of tools for the simulation of genomic side by side-generation sequencing data". Nature Reviews Genetics. 17 (eight): 459–69. doi:10.1038/nrg.2016.57. PMC5224698. PMID 27320129.
- ^ a b c d Lan, D., et al. 2021, Genozip: a universal extensible genomic data compressor, Bioinformatics
- ^ Ginart AA, Hui J, Zhu K, Numanagić I, Courtade TA, Sahinalp SC; et al. (2018). "Optimal compressed representation of loftier throughput sequence information via light associates". Nat Commun. 9 (i): 566. Bibcode:2018NatCo...ix..566G. doi:10.1038/s41467-017-02480-6. PMC5805770. PMID 29422526.
{{cite journal}}: CS1 maint: multiple names: authors listing (link) - ^ Zhu, Kaiyuan; Numanagić, Ibrahim; Sahinalp, Due south. Cenk (2018). "Genomic Data Compression". Encyclopedia of Large Data Technologies. Cham: Springer International Publishing. pp. 779–783. doi:x.1007/978-iii-319-63962-8_55-1. ISBN978-three-319-63962-8.
- ^ Numanagić, Ibrahim; Bonfield, James Yard; Hach, Faraz; Voges, January; Ostermann, Jörn; Alberti, Claudio; Mattavelli, Marco; Sahinalp, S Cenk (2016-10-24). "Comparing of loftier-throughput sequencing data compression tools". Nature Methods. Springer Scientific discipline and Business Media LLC. 13 (12): 1005–1008. doi:x.1038/nmeth.4037. ISSN 1548-7091. PMID 27776113. S2CID 205425373.
- ^ Ochoa, Idoia; Asnani, Himanshu; Bharadia, Dinesh; Chowdhury, Mainak; Weissman, Tsachy; Yona, Golan (2013). "Qual Comp: A new lossy compressor for quality scores based on charge per unit distortion theory". BMC Bioinformatics. fourteen: 187. doi:x.1186/1471-2105-14-187. PMC3698011. PMID 23758828.
- ^ Hach, F; Numanagic, I; Alkan, C; Sahinalp, S. C. (2012). "SCALCE: Boosting sequence pinch algorithms using locally consistent encoding". Bioinformatics. 28 (23): 3051–seven. doi:10.1093/bioinformatics/bts593. PMC3509486. PMID 23047557.
- ^ fastqz.http://mattmahoney.internet/dc/fastqz/
- ^ K. Hosseini, D. Pratas, and A. Pinho. 2016. A survey on data compression methods for biological sequences. Data 7(4):(2016): 56
- ^ Illumina Tech Notation.http://www.illumina.com/content/dam/illumina-marketing/documents/products/technotes/technote_understanding_quality_scores.pdf
- ^ Hosseini K, Pratas D, Pinho A (2018). Cryfa: a secure encryption tool for genomic data. Bioinformatics. Vol. 35. pp. 146–148. doi:10.1093/bioinformatics/bty645. PMC6298042. PMID 30020420.
External links [edit]
- MAQ webpage discussing FASTQ variants
Source: https://en.wikipedia.org/wiki/FASTQ_format
0 Response to "Number of Sequence Reads Is Not Good Indicator of Sample Quality"
Post a Comment